Example
Below we give a full example on how Phosphorpy can be used. The example shows most of the functionality and provides an overview what Phosphorpy is able to do.
To start, we have to create a DataSet, the central object which provides the interface to the different subsections like the coordinates, magnitudes, ... . There are two ways to do this. The first one is using a file of coordinates and the second one is by starting with a constrained query of a Vizier catalog.
For this example we will use a file with equatorial coordinates ('my_coordinates.fits'). The file doesn't have to be a fits-table, it can be also a csv-file (other formats are not supported at the moment). Our file has two columns, the first is named 'RAJ2000' and the second one 'DEJ2000'. By default the column names are set to 'ra' and 'dec', if the names of the columns are different we have to provide those different column names too.
from Phosphorpy import DataSet
ds = DataSet.load_coordinates('./my_coordinates.fits',
ra_name='ra', dec_name='dec')Now we have a DataSet with a set of coordinates. We can plot the positions of the coordinates. First in the equatorial system
ds.plot.equatorial_coordinates()
or in Galactic coordinates
ds.plot.galactic_coordinates()
The coordinate system can do more and we will come back to that later.
We might want more information of objects at the provided coordinates, such as magnitudes. So, we have to get them from catalogs. As is described in magnitudes, we use the Vizier database as source of the data. Vizier contains catalogues of most of the current surveys.
We will use all available survey data: at the moment data is available from the SDSS, Pan-STARRS, KiDS, GALEX, 2MASS, VIKING, UKIDSS, Gaia and WISE surveys. We can give all the survey names in an array or call load_from_vizier each time for each survey individually with the respective survey name as input:
surveys = ['SDSS', 'Pan-STARRS', 'KiDS', 'GALEX',
'2MASS', 'VIKING', 'UKIDSS', 'Gaia', 'WISE']
ds.load_from_vizier(surveys)
# or alternatively:
#for s in surveys:
# ds.load_from_vizier(s)Both versions give the same result. Alternatively, you can give 'all' as input parameter to load_from_vizier
#ds.load_from_vizier('all')Another option, if just the optical data are required, you can use the key word 'optical' or if you want the NIR surveys, use 'NIR' (this keyword is not case sensitive).
After the download of the survey information is finished we can take a look at the distribution of the magnitudes (note downloading the survey data can take a while if the list of coordinates is long). In the case of the coordinates, we can go via the magnitudes object or direct to the plotting environment.
ds.magnitudes.plot.hist(['u', 'g'])
# or direct
ds.plot.magnitude_hist(['u', 'g'])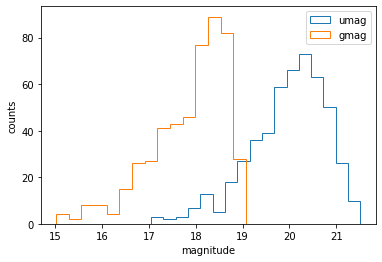
Depending on the area on the sky and on the goal of your query it might be necessary to correct the magnitudes for the effect of Galactic extinction. Phosphorpy is able to do that with just one call. Based on the InfraRed Science Archive (IRSA) dust map the package extinction is used to compute the extinction correction.
To apply the extinction correction just do
ds.correct_extinction()But keep in mind that the IRSA dust map has a resolution of a few arcminutes and therefore the extinction correction is interpolated to the coordinate of interest. Thus, especially for fields in the Galactic Plane where the extinction may well vary over angular scales less than a few arcminutes, the extinction correction is approximated. Also, it is important to mention that the extinction correction will overwrite the original data of the magnitudes!
After obtaining the magnitudes for all objects in our search, the logical next step is to investigate their colors.
Phosphorpy has therefore a system to compute the colors.
The easiest way to compute the colors of all downloaded surveys is by calling the colors variable in the following way:
ds.colorsActually, it is not necessary to do this explicitly. Phosphorpy will compute the colors on the fly if the command ds.colors is part of a longer command. For example if you want to display a color-color diagram using the 2MASS survey, one can write directly:
ds.colors.plot.color_color('2mass')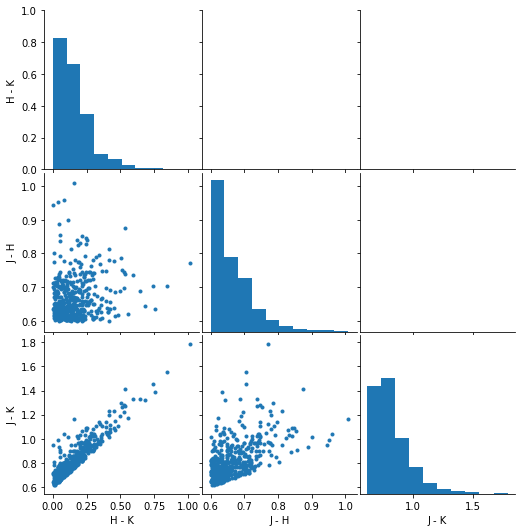
Besides the actual use of colors to identify the object, colors can also be used to detect outliers in the data. An outlier is an object, whose colors are not in or close to the majority of the astrophysical objects (see outlier detection for more details). To let Phosphorpy find the outliers you have to call the method outlier_detection
ds.colors.outlier_detection('2mass')
ds.colors.plot.color_color('2mass')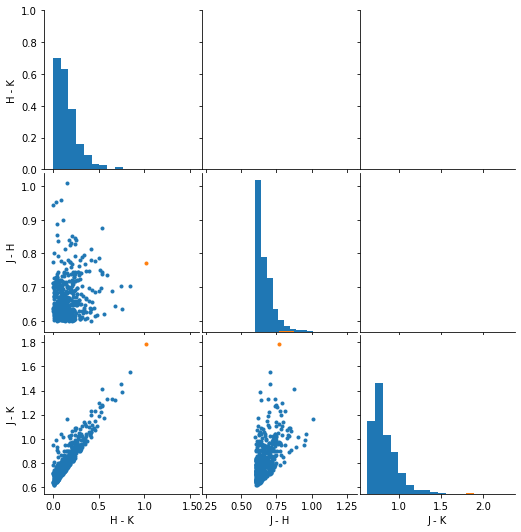
Like colors, fluxes can be useful for many purposes. Therefore Phosphorpy includes also an automatic system to compute the fluxes of the implemented surveys and as before, it uses a basic plotting environment.
To compute the fluxes, you have to do the same as in the case of colors. Just call:
ds.fluxThe flux environment has a fitting system. For instance, if we want to fit the data with a 4th order polynomial one types:
ds.flux.fit_polynomial(4)| a | b | c | d | e | |
|---|---|---|---|---|---|
| 1 | -2.067629e-33 | 2.015757e-28 | -6.196128e-24 | 5.993668e-20 | -2.003484e-17 |
| 2 | -4.138011e-33 | 3.963189e-28 | -1.172494e-23 | 1.000606e-19 | 1.361475e-16 |
| 3 | -2.081493e-34 | 3.880132e-29 | -2.071190e-24 | 3.296035e-20 | 2.577493e-17 |
| 4 | -1.176309e-32 | 1.159933e-27 | -3.652706e-23 | 3.800703e-19 | -4.867637e-16 |
| 5 | -3.356504e-33 | 3.177700e-28 | -9.171493e-24 | 7.175809e-20 | 1.851798e-16 |
| ... | ... | ... | ... | ... | ... |
| 495 | -2.038604e-32 | 1.987630e-27 | -6.140033e-23 | 6.149330e-19 | -6.648420e-16 |
| 496 | -3.368204e-33 | 3.350524e-28 | -1.065340e-23 | 1.103056e-19 | -7.988860e-17 |
| 497 | -2.086273e-32 | 2.091155e-27 | -6.755090e-23 | 7.322413e-19 | -9.765266e-16 |
| 498 | -1.327501e-32 | 1.317153e-27 | -4.171642e-23 | 4.292070e-19 | -3.027100e-16 |
| 499 | -1.141677e-33 | 1.416183e-28 | -6.046936e-24 | 9.690600e-20 | -3.300758e-16 |
499 rows x 5 columns
The results of the fit can be then obtained via
fitting_results = ds.flux.fitThe plotting environment of the flux section provides only one plot at the moment. This is a plot of the spectral energy distribution (SED). To plot the SED with the number 4, you have to write
ds.flux.plot.sed(4, x_log=True, y_log=True)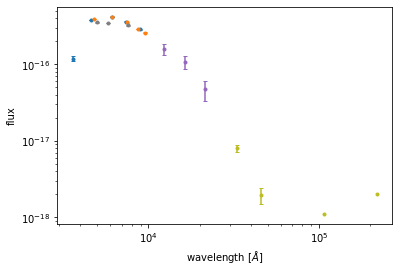
and Phosphorpy will create an SED plot with logarithmic x- and y-axis.
Besides the data from the major astronomical catalogs, there are many other catalogues available, which can be useful if they are connected to an existing data set. At the moment Phosphorpy is not able to connect many catalogues if they are not available in Vizier (see external data for details) but three additional data sources are implemented.
The first two external catalogues are those providing images from SDSS and Pan-STARRS. As before, the interface to get the image(s) is simple: one has to call one of two methods to download them. The call to download a single image from SDSS or Pan-STARRS is images and the second command to download all images / the images of all coordinates in the input list from SDSS or Pan-STARRS is all_images
As inputs the survey name, the id of the coordinates are required (if the method is images), and the directory to store the image are required.
ds.images('PS', 4, './images')
# or if all images are wanted
ds.all_images('PS', './images')
The other external source of data available is the Catalina Sky Survey, which may provide well sampled light curves for selected sources.
ds.light_curvesNumber of light curves: 500
with 148631 entries.
Keep in mind that both queries take much more time to run than the average catalog query. Especially in the case of many sources it can take a while before all the data is downloaded. This has nothing to do with Phosphorpy, it is because of server response.