{kind=link}
{kind=link}
{kind=link}
Este projeto implementa um sistema de RAG (Retrieval-Augmented Generation) utilizando LangChain, FAISS para indexação vetorial, embeddings do Hugging Face e modelos LLM via OpenRouter.
O objetivo é responder perguntas de forma contextualizada com base em um documento PDF.
Para demonstração, foi utilizado um PDF contendo receitas de bolos caseiros, servindo como exemplo de aplicação prática.
- 📂 Carregamento de documentos no formato PDF.
- ✂️ Divisão inteligente do texto em chunks com sobreposição para manter o contexto.
- 🧩 Geração de embeddings vetoriais utilizando modelos do Hugging Face.
- 🔎 Indexação com FAISS para busca semântica rápida e eficiente.
- 🤖 Integração com modelos LLM via OpenRouter.
- ✅ Respostas sempre baseadas no documento fornecido, evitando alucinações.
├── app.py # Interface com Streamlit
├── rag.py # Núcleo do RAG: carregamento, indexação e resposta
├── receitas_bolos.pdf # Documento de referência
├── requirements.txt # Dependências do projeto
└── README.md
Se ainda não tiver o Conda, você pode instalar o Miniconda (mais leve) ou o Anaconda.
Exemplo de instalação do Miniconda no Linux/macOS:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
curl -LO https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh
bash Miniconda3-latest-*.sh
No Windows, basta baixar o instalador gráfico do site oficial e seguir os passos.
Depois da instalação, reinicie o terminal e verifique:
conda --version
⸻
- Crie e ative o ambiente virtual
conda create -n rag-env python=3.12 -y
conda activate rag-env
⸻
- Clone o repositório
git clone https://github.com/seu-usuario/seu-repo.git
cd seu-repo
⸻
- Instale as dependências
pip install -r requirements.txt
⸻
- Configure as variáveis de ambiente
Crie um arquivo .env na raiz do projeto:
OPENROUTER_API_KEY=sk-or-xxxxxxxxxxxxxxxxxxxxxxxx
⸻
- Execute a aplicação
Rode interface Streamlit:
streamlit run app.py
⸻
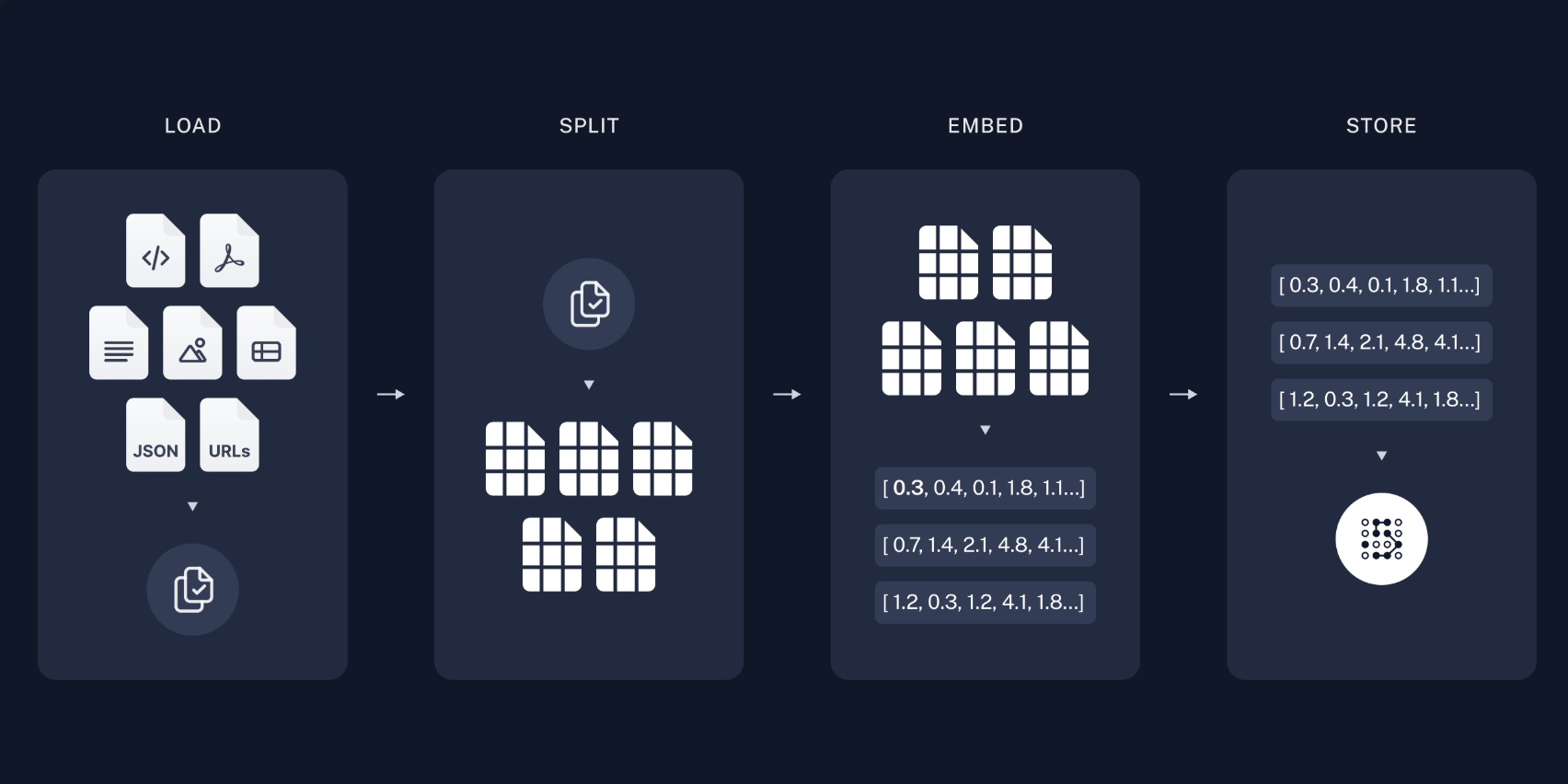
loader = PyMuPDFLoader("receitas_bolos.pdf")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = splitter.split_documents(docs)
vectorstore = FAISS.from_documents(splits, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
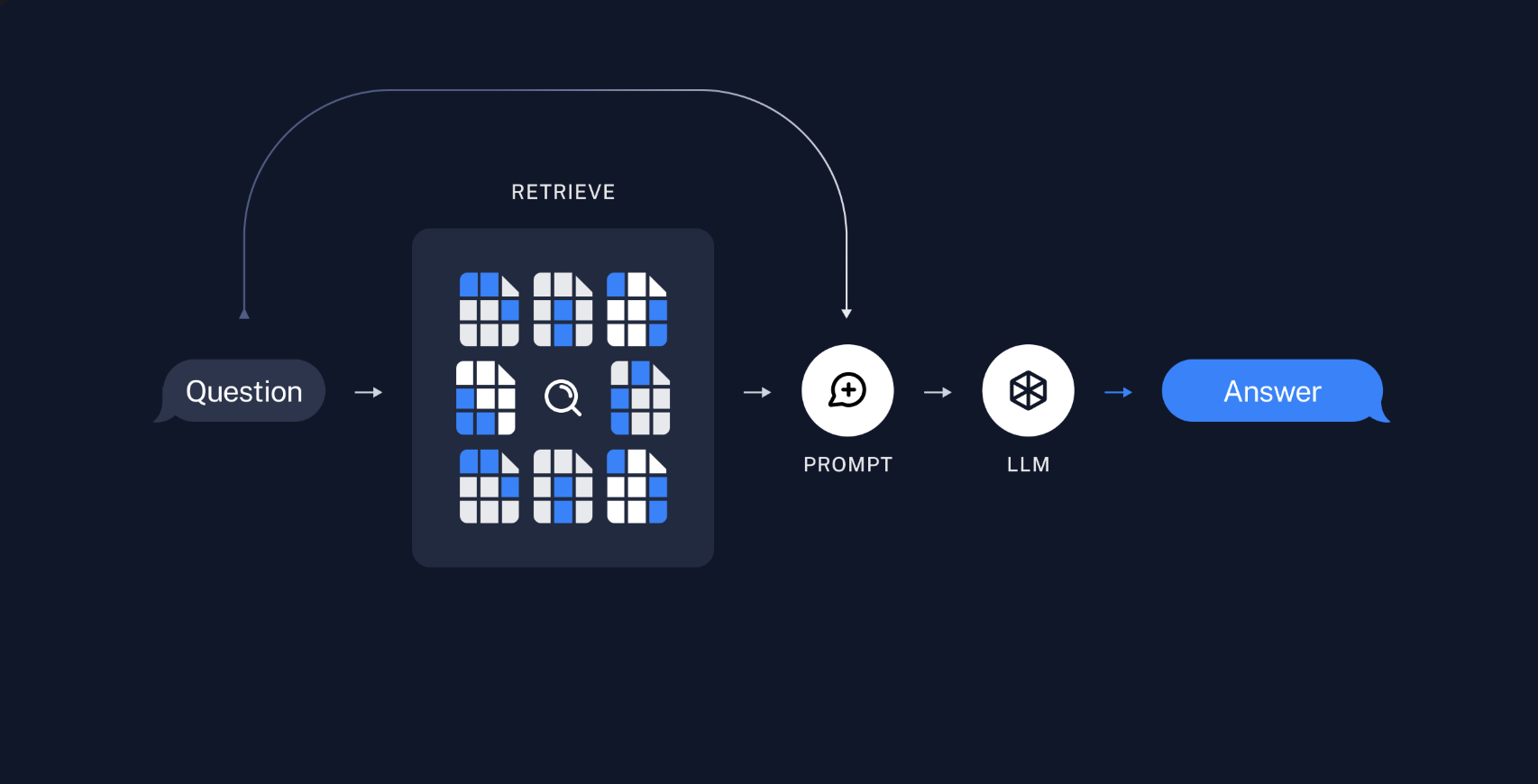
def responder_pergunta(pergunta: str) -> str:
docs = retriever.invoke(pergunta)
contexto = "\n\n".join([d.page_content for d in docs])
mensagens = prompt.format_messages(context=contexto, question=pergunta)
resposta = llm.invoke(mensagens)
return resposta.content
⸻
- LangChain – Orquestração do fluxo RAG.
- FAISS – Indexação e busca vetorial semântica.
- Hugging Face Sentence Transformers – Criação de embeddings.
- OpenRouter – Acesso a modelos LLM.
- Streamlit – Interface interativa (opcional).
- Conda – Gerenciamento de ambientes.
- As respostas são sempre extraídas do PDF fornecido.
- Caso a pergunta não esteja relacionada ao documento, o modelo responde educadamente que não pode responder.
- O modelo padrão é mistralai/mistral-7b-instruct:free, mas pode ser substituído por outros disponíveis no catálogo do OpenRouter.
⸻
Autor: Gabriel W. A. Matias