diff --git a/GLADNet2.0/README.md b/GLADNet2.0/README.md
new file mode 100644
index 0000000..98aeab3
--- /dev/null
+++ b/GLADNet2.0/README.md
@@ -0,0 +1,82 @@
+# GLADNet
+
+This is a Tensorflow implantation of GLADNet
+
+GLADNet: Low-Light Enhancement Network with Global Awareness. In [FG'18](https://fg2018.cse.sc.edu/index.html) Workshop [FOR-LQ 2018](http://staff.ustc.edu.cn/~dongeliu/forlq2018/index.html)
+[Wenjing Wang*](https://daooshee.github.io/website/), [Chen Wei*](https://weichen582.github.io/), [Wenhan Yang](https://flyywh.github.io/), [Jiaying Liu](http://www.icst.pku.edu.cn/struct/people/liujiaying.html). (* indicates equal contributions)
+
+[Paper](http://www.icst.pku.edu.cn/F/course/icb/Pub%20Files/2018/wwj_fg2018.pdf), [Project Page](https://daooshee.github.io/fgworkshop18Gladnet/)
+
+
+
+## Requirements ##
+1. Python
+2. Tensorflow >= 1.3.0
+3. numpy, PIL
+
+## Testing Usage ##
+To quickly test your own images with our model, you can just run through
+```shell
+python main.py
+ --use_gpu=1 \ # use gpu or not
+ --gpu_idx=0 \
+ --gpu_mem=0.5 \ # gpu memory usage
+ --phase=test \
+ --test_dir=/path/to/your/test/dir/ \
+ --save_dir=/path/to/save/results/ \
+```
+## Training Usage ##
+First, download training data set from [our project page](https://daooshee.github.io/fgworkshop18Gladnet/). Save training pairs of our LOL dataset under `./data/train/low/`, and synthetic pairs under `./data/train/normal/`.
+Then, start training by
+```shell
+python main.py
+ --use_gpu=1 \ # use gpu or not
+ --gpu_idx=0 \
+ --gpu_mem=0.8 \ # gpu memory usage
+ --phase=train \
+ --epoch=50 \ # number of training epoches
+ --batch_size=8 \
+ --patch_size=384 \ # size of training patches
+ --base_lr=0.001 \ # initial learning rate for adm
+ --eval_every_epoch=5 \ # evaluate and save checkpoints for every # epoches
+ --checkpoint_dir=./checkpoint # if it is not existed, automatically make dirs
+ --sample_dir=./sample # dir for saving evaluation results during training
+ ```
+
+ ## Experiment Results ##
+ #### Subjective Results ####
+ 
+ #### Objective Results ####
+We use the [Naturalness Image Quality Evaluator (NIQE)](https://ieeexplore.ieee.org/document/6353522) no-reference image quality score for quantitative comparison. NIQE compares images to a default model computed from images of natural scenes. A smaller score indicates better perceptual quality.
+
+| Dataset | DICM | NPE | MEF | Average |
+| ------ | ------ | ------ | ------ | ------ |
+| MSRCR | 3.117 | 3.369 | 4.362 | 3.586 |
+| LIME | 3.243 | 3.649 | 4.745 | 3.885 |
+| DeHZ | 3.608 | 4.258 | 5.071 | 4.338 |
+| SRIE | 2.975 | 3.127 | 4.042 | 3.381 |
+| GLADNet | 2.761 | 3.278 | 3.468 | 3.184 |
+ #### Computer Vision Application ####
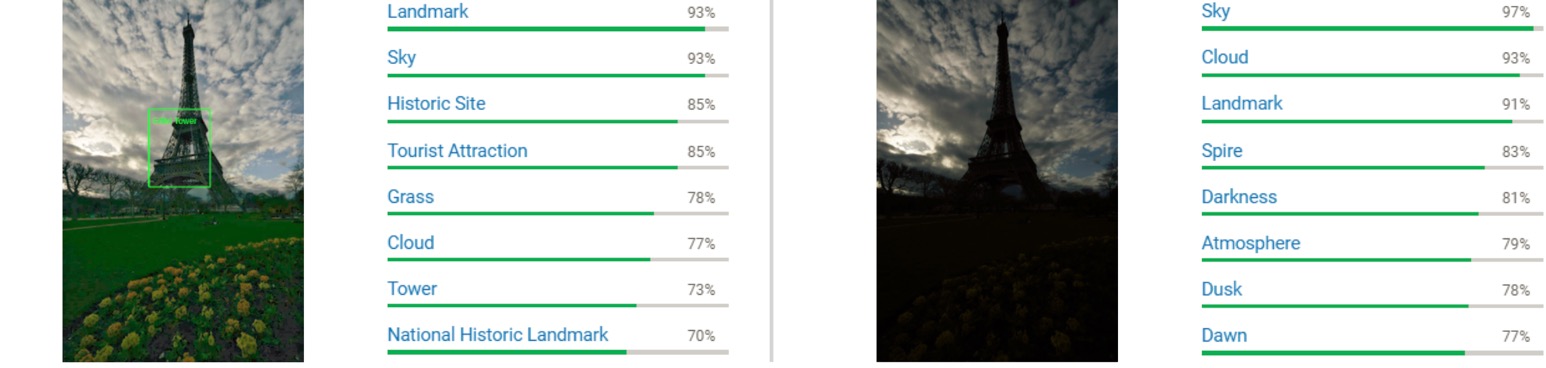
+ We test several real low-light images and their corresponding enhanced results on [Google Cloud Visio API](https://cloud.google.com/vision/). GLADNet helps it to identify the objects in this image.
+
+
+ 
+
+
+ 
+
+ ## Citation ##
+ ```
+@inproceedings{wang2018gladnet,
+ title={GLADNet: Low-Light Enhancement Network with Global Awareness},
+ author={Wang, Wenjing and Wei, Chen and Yang, Wenhan and Liu, Jiaying},
+ booktitle={Automatic Face \& Gesture Recognition (FG 2018), 2018 13th IEEE International Conference},
+ pages={751--755},
+ year={2018},
+ organization={IEEE}
+}
+```
+
+## Related Follow-Up Work ##
+Deep Retinex Decomposition: Deep Retinex Decomposition for Low-Light Enhancement. Chen Wei*, Wenjing Wang*, Wenhan Yang, Jiaying Liu. (* indicates equal contributions) In BMVC'18 (Oral Presentation) [Website](https://daooshee.github.io/BMVC2018website/) [Github](https://github.com/weichen582/RetinexNet)
+
diff --git a/GLADNet2.0/__pycache__/model.cpython-36.pyc b/GLADNet2.0/__pycache__/model.cpython-36.pyc
new file mode 100644
index 0000000..7afdd39
Binary files /dev/null and b/GLADNet2.0/__pycache__/model.cpython-36.pyc differ
diff --git a/GLADNet2.0/__pycache__/utils.cpython-36.pyc b/GLADNet2.0/__pycache__/utils.cpython-36.pyc
new file mode 100644
index 0000000..51dae8d
Binary files /dev/null and b/GLADNet2.0/__pycache__/utils.cpython-36.pyc differ
diff --git a/GLADNet2.0/data/eval/low/4.bmp b/GLADNet2.0/data/eval/low/4.bmp
new file mode 100644
index 0000000..59199af
Binary files /dev/null and b/GLADNet2.0/data/eval/low/4.bmp differ
diff --git a/GLADNet2.0/data/eval/low/chinese_garden3.png b/GLADNet2.0/data/eval/low/chinese_garden3.png
new file mode 100644
index 0000000..23f3a99
Binary files /dev/null and b/GLADNet2.0/data/eval/low/chinese_garden3.png differ
diff --git a/GLADNet2.0/data/eval/low/kluki1.png b/GLADNet2.0/data/eval/low/kluki1.png
new file mode 100644
index 0000000..4131c3b
Binary files /dev/null and b/GLADNet2.0/data/eval/low/kluki1.png differ
diff --git a/GLADNet2.0/main.py b/GLADNet2.0/main.py
new file mode 100644
index 0000000..0ebe093
--- /dev/null
+++ b/GLADNet2.0/main.py
@@ -0,0 +1,112 @@
+from __future__ import print_function
+import os
+import argparse
+from glob import glob
+
+from PIL import Image
+import tensorflow as tf
+
+from model import lowlight_enhance
+from utils import *
+
+parser = argparse.ArgumentParser(description='')
+
+parser.add_argument('--use_gpu', dest='use_gpu', type=int, default=1, help='gpu flag, 1 for GPU and 0 for CPU')
+parser.add_argument('--gpu_idx', dest='gpu_idx', default="0", help='GPU idx')
+parser.add_argument('--gpu_mem', dest='gpu_mem', type=float, default=0.8, help="0 to 1, gpu memory usage")
+parser.add_argument('--phase', dest='phase', default='train', help='train or test')
+
+parser.add_argument('--epoch', dest='epoch', type=int, default=50, help='number of total epoches')
+parser.add_argument('--batch_size', dest='batch_size', type=int, default=8, help='number of samples in one batch')
+parser.add_argument('--patch_size', dest='patch_size', type=int, default=384, help='patch size')
+parser.add_argument('--eval_every_epoch', dest='eval_every_epoch', default=1, help='evaluating and saving checkpoints every # epoch')
+parser.add_argument('--checkpoint_dir', dest='ckpt_dir', default='./checkpoint', help='directory for checkpoints')
+parser.add_argument('--sample_dir', dest='sample_dir', default='./sample', help='directory for evaluating outputs')
+
+parser.add_argument('--save_dir', dest='save_dir', default='./test_results', help='directory for testing outputs')
+parser.add_argument('--test_dir', dest='test_dir', default='./data/test/low', help='directory for testing inputs')
+
+args = parser.parse_args()
+
+def lowlight_train(lowlight_enhance):
+ if not os.path.exists(args.ckpt_dir):
+ os.makedirs(args.ckpt_dir)
+ if not os.path.exists(args.sample_dir):
+ os.makedirs(args.sample_dir)
+
+ train_low_data = []
+ train_high_data = []
+
+ train_low_data_names = glob('/mnt/hdd/wangwenjing/FGtraining/low/*.png')#./data/train/low/*.png')
+ train_low_data_names.sort()
+ train_high_data_names = glob('/mnt/hdd/wangwenjing/FGtraining/normal/*.png')#./data/train/normal/*.png')
+ train_high_data_names.sort()
+ assert len(train_low_data_names) == len(train_high_data_names)
+ print('[*] Number of training data: %d' % len(train_low_data_names))
+
+ for idx in range(len(train_low_data_names)):
+ if (idx + 1) % 1000 == 0:
+ print(idx + 1)
+ low_im = load_images(train_low_data_names[idx])
+ train_low_data.append(low_im)
+ high_im = load_images(train_high_data_names[idx])
+ train_high_data.append(high_im)
+
+ eval_low_data = []
+ eval_high_data = []
+
+ eval_low_data_name = glob('./data/eval/low/*.*')
+
+ for idx in range(len(eval_low_data_name)):
+ eval_low_im = load_images(eval_low_data_name[idx])
+ eval_low_data.append(eval_low_im)
+
+ lowlight_enhance.train(train_low_data, train_high_data, eval_low_data, batch_size=args.batch_size, patch_size=args.patch_size, epoch=args.epoch, sample_dir=args.sample_dir, ckpt_dir=args.ckpt_dir, eval_every_epoch=args.eval_every_epoch)
+
+
+def lowlight_test(lowlight_enhance):
+ if args.test_dir == None:
+ print("[!] please provide --test_dir")
+ exit(0)
+
+ if not os.path.exists(args.save_dir):
+ os.makedirs(args.save_dir)
+
+ test_low_data_name = glob(os.path.join(args.test_dir) + '/*.*')
+ test_low_data = []
+ test_high_data = []
+ for idx in range(len(test_low_data_name)):
+ test_low_im = load_images(test_low_data_name[idx])
+ test_low_data.append(test_low_im)
+
+ lowlight_enhance.test(test_low_data, test_high_data, test_low_data_name, save_dir=args.save_dir)
+
+
+def main(_):
+ if args.use_gpu:
+ print("[*] GPU\n")
+ os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu_idx
+ gpu_options = tf.compat.v1.GPUOptions(per_process_gpu_memory_fraction=args.gpu_mem)
+ with tf.compat.v1.Session(config=tf.compat.v1.ConfigProto(gpu_options=gpu_options)) as sess:
+ model = lowlight_enhance(sess)
+ if args.phase == 'train':
+ lowlight_train(model)
+ elif args.phase == 'test':
+ lowlight_test(model)
+ else:
+ print('[!] Unknown phase')
+ exit(0)
+ else:
+ print("[*] CPU\n")
+ with tf.compat.v1.Session() as sess:
+ model = lowlight_enhance(sess)
+ if args.phase == 'train':
+ lowlight_train(model)
+ elif args.phase == 'test':
+ lowlight_test(model)
+ else:
+ print('[!] Unknown phase')
+ exit(0)
+
+if __name__ == '__main__':
+ tf.compat.v1.app.run()
diff --git a/GLADNet2.0/model.py b/GLADNet2.0/model.py
new file mode 100644
index 0000000..0650736
--- /dev/null
+++ b/GLADNet2.0/model.py
@@ -0,0 +1,185 @@
+from __future__ import print_function
+
+import os
+import time
+import random
+
+from PIL import Image
+import tensorflow as tf
+import numpy as np
+
+from utils import *
+
+def FG(input_im):
+ with tf.compat.v1.variable_scope('FG'):
+ input_rs = tf.image.resize(input_im, (96, 96), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
+
+ p_conv1 = tf.compat.v1.layers.conv2d(input_rs, 64, 3, 2, padding='same', activation=tf.nn.relu) # 48
+ p_conv2 = tf.compat.v1.layers.conv2d(p_conv1, 64, 3, 2, padding='same', activation=tf.nn.relu) # 24
+ p_conv3 = tf.compat.v1.layers.conv2d(p_conv2, 64, 3, 2, padding='same', activation=tf.nn.relu) # 12
+ p_conv4 = tf.compat.v1.layers.conv2d(p_conv3, 64, 3, 2, padding='same', activation=tf.nn.relu) # 6
+ p_conv5 = tf.compat.v1.layers.conv2d(p_conv4, 64, 3, 2, padding='same', activation=tf.nn.relu) # 3
+ p_conv6 = tf.compat.v1.layers.conv2d(p_conv5, 64, 3, 2, padding='same', activation=tf.nn.relu) # 1
+
+ p_deconv1 = tf.image.resize(p_conv6, (3, 3), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
+ p_deconv1 = tf.compat.v1.layers.conv2d(p_deconv1, 64, 3, 1, padding='same', activation=tf.nn.relu)
+ p_deconv1 = p_deconv1 + p_conv5
+ p_deconv2 = tf.image.resize(p_deconv1, (6, 6), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
+ p_deconv2 = tf.compat.v1.layers.conv2d(p_deconv2, 64, 3, 1, padding='same', activation=tf.nn.relu)
+ p_deconv2 = p_deconv2 + p_conv4
+ p_deconv3 = tf.image.resize(p_deconv2, (12, 12), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
+ p_deconv3 = tf.compat.v1.layers.conv2d(p_deconv3, 64, 3, 1, padding='same', activation=tf.nn.relu)
+ p_deconv3 = p_deconv3 + p_conv3
+ p_deconv4 = tf.image.resize(p_deconv3, (24, 24), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
+ p_deconv4 = tf.compat.v1.layers.conv2d(p_deconv4, 64, 3, 1, padding='same', activation=tf.nn.relu)
+ p_deconv4 = p_deconv4 + p_conv2
+ p_deconv5 = tf.image.resize(p_deconv4, (48, 48), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
+ p_deconv5 = tf.compat.v1.layers.conv2d(p_deconv5, 64, 3, 1, padding='same', activation=tf.nn.relu)
+ p_deconv5 = p_deconv5 + p_conv1
+ p_deconv6 = tf.image.resize(p_deconv5, (96, 96), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
+ p_deconv6 = tf.compat.v1.layers.conv2d(p_deconv6, 64, 3, 1, padding='same', activation=tf.nn.relu)
+
+ p_output = tf.image.resize(p_deconv6, (tf.shape(input=input_im)[1], tf.shape(input=input_im)[2]), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
+
+ a_input = tf.concat([p_output, input_im], axis=3)
+ a_conv1 = tf.compat.v1.layers.conv2d(a_input, 128, 3, 1, padding='same', activation=tf.nn.relu)
+ a_conv2 = tf.compat.v1.layers.conv2d(a_conv1, 128, 3, 1, padding='same', activation=tf.nn.relu)
+ a_conv3 = tf.compat.v1.layers.conv2d(a_conv2, 128, 3, 1, padding='same', activation=tf.nn.relu)
+ a_conv4 = tf.compat.v1.layers.conv2d(a_conv3, 128, 3, 1, padding='same', activation=tf.nn.relu)
+ a_conv5 = tf.compat.v1.layers.conv2d(a_conv4, 3, 3, 1, padding='same', activation=tf.nn.relu)
+ return a_conv5
+
+
+
+class lowlight_enhance(object):
+ def __init__(self, sess):
+ self.sess = sess
+ self.base_lr = 0.001
+
+ self.input_low = tf.compat.v1.placeholder(tf.float32, [None, None, None, 3], name='input_low')
+ self.input_high = tf.compat.v1.placeholder(tf.float32, [None, None, None, 3], name='input_high')
+
+ self.output = FG(self.input_low)
+ self.loss = tf.reduce_mean(input_tensor=tf.abs((self.output - self.input_high) * [[[[0.11448, 0.58661, 0.29891]]]]))
+
+ self.global_step = tf.Variable(0, trainable = False)
+ self.lr = tf.compat.v1.train.exponential_decay(self.base_lr, self.global_step, 100, 0.96)
+ optimizer = tf.compat.v1.train.AdamOptimizer(self.lr, name='AdamOptimizer')
+ self.train_op = optimizer.minimize(self.loss, global_step=self.global_step)
+
+ self.sess.run(tf.compat.v1.global_variables_initializer())
+ self.saver = tf.compat.v1.train.Saver()
+ print("[*] Initialize model successfully...")
+
+ def evaluate(self, epoch_num, eval_low_data, sample_dir):
+ print("[*] Evaluating for epoch %d..." % (epoch_num))
+
+ for idx in range(len(eval_low_data)):
+ input_low_eval = np.expand_dims(eval_low_data[idx], axis=0)
+ result = self.sess.run(self.output, feed_dict={self.input_low: input_low_eval})
+ save_images(os.path.join(sample_dir, 'eval_%d_%d.png' % (idx + 1, epoch_num)), input_low_eval, result)
+
+
+ def train(self, train_low_data, train_high_data, eval_low_data, batch_size, patch_size, epoch, sample_dir, ckpt_dir, eval_every_epoch):
+
+ assert len(train_low_data) == len(train_high_data)
+ numBatch = len(train_low_data) // int(batch_size)
+
+ load_model_status, global_step = self.load(self.saver, ckpt_dir)
+ if load_model_status:
+ iter_num = global_step
+ start_epoch = global_step // numBatch
+ start_step = global_step % numBatch
+ print("[*] Model restore success!")
+ else:
+ iter_num = 0
+ start_epoch = 0
+ start_step = 0
+ print("[*] Not find pretrained model!")
+
+ print("[*] Start training with start epoch %d start iter %d : " % (start_epoch, iter_num))
+
+ start_time = time.time()
+ image_id = 0
+
+ for epoch in range(start_epoch, epoch):
+ for batch_id in range(start_step, numBatch):
+ # generate data for a batch
+ batch_input_low = np.zeros((batch_size, patch_size, patch_size, 3), dtype="float32")
+ batch_input_high = np.zeros((batch_size, patch_size, patch_size, 3), dtype="float32")
+ for patch_id in range(batch_size):
+ h, w, _ = train_low_data[image_id].shape
+ x = random.randint(0, h - patch_size)
+ y = random.randint(0, w - patch_size)
+
+ rand_mode = random.randint(0, 7)
+ batch_input_low[patch_id, :, :, :] = data_augmentation(train_low_data[image_id][x : x+patch_size, y : y+patch_size, :], rand_mode)
+ batch_input_high[patch_id, :, :, :] = data_augmentation(train_high_data[image_id][x : x+patch_size, y : y+patch_size, :], rand_mode)
+
+ image_id = (image_id + 1) % len(train_low_data)
+ if image_id == 0:
+ tmp = list(zip(train_low_data, train_high_data))
+ random.shuffle(list(tmp))
+ train_low_data, train_high_data = zip(*tmp)
+
+ # train
+ _, loss = self.sess.run([self.train_op, self.loss], feed_dict={self.input_low: batch_input_low, \
+ self.input_high: batch_input_high})
+
+ print("Epoch: [%2d] [%4d/%4d] time: %4.4f, loss: %.6f" \
+ % (epoch + 1, batch_id + 1, numBatch, time.time() - start_time, loss))
+ iter_num += 1
+
+ # evalutate the model and save a checkpoint file for it
+ if (epoch + 1) % eval_every_epoch == 0:
+ self.evaluate(epoch + 1, eval_low_data, sample_dir=sample_dir)
+ self.save(self.saver, iter_num, ckpt_dir, "GLADNet")
+
+ print("[*] Finish training")
+
+ def save(self, saver, iter_num, ckpt_dir, model_name):
+ if not os.path.exists(ckpt_dir):
+ os.makedirs(ckpt_dir)
+ print("[*] Saving model %s" % model_name)
+ saver.save(self.sess, \
+ os.path.join(ckpt_dir, model_name), \
+ global_step=iter_num)
+
+ def load(self, saver, ckpt_dir):
+ ckpt = tf.train.get_checkpoint_state(ckpt_dir)
+ if ckpt and ckpt.model_checkpoint_path:
+ full_path = tf.train.latest_checkpoint(ckpt_dir)
+ try:
+ global_step = int(full_path.split('/')[-1].split('-')[-1])
+ except ValueError:
+ global_step = None
+ saver.restore(self.sess, full_path)
+ return True, global_step
+ else:
+ print("[*] Failed to load model from %s" % ckpt_dir)
+ return False, 0
+
+ def test(self, test_low_data, test_high_data, test_low_data_names, save_dir):
+ tf.compat.v1.global_variables_initializer().run()
+
+ print("[*] Reading checkpoint...")
+ load_model_status, _ = self.load(self.saver, './model/')
+ if load_model_status:
+ print("[*] Load weights successfully...")
+
+ print("[*] Testing...")
+ total_run_time = 0.0
+ for idx in range(len(test_low_data)):
+ print(test_low_data_names[idx])
+ [_, name] = os.path.split(test_low_data_names[idx])
+ suffix = name[name.find('.') + 1:]
+ name = name[:name.find('.')]
+
+ input_low_test = np.expand_dims(test_low_data[idx], axis=0)
+ start_time = time.time()
+ result = self.sess.run(self.output, feed_dict = {self.input_low: input_low_test})
+ total_run_time += time.time() - start_time
+ save_images(os.path.join(save_dir, name + "_glad." + suffix), result)
+
+ ave_run_time = total_run_time / float(len(test_low_data))
+ print("[*] Average run time: %.4f" % ave_run_time)
diff --git a/GLADNet2.0/model/GLADNet.data-00000-of-00001 b/GLADNet2.0/model/GLADNet.data-00000-of-00001
new file mode 100644
index 0000000..9b7af96
Binary files /dev/null and b/GLADNet2.0/model/GLADNet.data-00000-of-00001 differ
diff --git a/GLADNet2.0/model/GLADNet.index b/GLADNet2.0/model/GLADNet.index
new file mode 100644
index 0000000..70dac6b
Binary files /dev/null and b/GLADNet2.0/model/GLADNet.index differ
diff --git a/GLADNet2.0/model/GLADNet.meta b/GLADNet2.0/model/GLADNet.meta
new file mode 100644
index 0000000..e74b96e
Binary files /dev/null and b/GLADNet2.0/model/GLADNet.meta differ
diff --git a/GLADNet2.0/model/checkpoint b/GLADNet2.0/model/checkpoint
new file mode 100644
index 0000000..d4dd250
--- /dev/null
+++ b/GLADNet2.0/model/checkpoint
@@ -0,0 +1,2 @@
+model_checkpoint_path: "GLADNet"
+all_model_checkpoint_paths: "GLADNet"
diff --git a/GLADNet2.0/results/4_glad.bmp b/GLADNet2.0/results/4_glad.bmp
new file mode 100644
index 0000000..cd34b98
Binary files /dev/null and b/GLADNet2.0/results/4_glad.bmp differ
diff --git a/GLADNet2.0/results/chinese_garden3_glad.png b/GLADNet2.0/results/chinese_garden3_glad.png
new file mode 100644
index 0000000..18a782c
Binary files /dev/null and b/GLADNet2.0/results/chinese_garden3_glad.png differ
diff --git a/GLADNet2.0/results/kluki1_glad.png b/GLADNet2.0/results/kluki1_glad.png
new file mode 100644
index 0000000..5ec25f9
Binary files /dev/null and b/GLADNet2.0/results/kluki1_glad.png differ
diff --git a/GLADNet2.0/utils.py b/GLADNet2.0/utils.py
new file mode 100644
index 0000000..6fc320c
--- /dev/null
+++ b/GLADNet2.0/utils.py
@@ -0,0 +1,47 @@
+import numpy as np
+from PIL import Image
+
+def data_augmentation(image, mode):
+ if mode == 0:
+ # original
+ return image
+ elif mode == 1:
+ # flip up and down
+ return np.flipud(image)
+ elif mode == 2:
+ # rotate counterwise 90 degree
+ return np.rot90(image)
+ elif mode == 3:
+ # rotate 90 degree and flip up and down
+ image = np.rot90(image)
+ return np.flipud(image)
+ elif mode == 4:
+ # rotate 180 degree
+ return np.rot90(image, k=2)
+ elif mode == 5:
+ # rotate 180 degree and flip
+ image = np.rot90(image, k=2)
+ return np.flipud(image)
+ elif mode == 6:
+ # rotate 270 degree
+ return np.rot90(image, k=3)
+ elif mode == 7:
+ # rotate 270 degree and flip
+ image = np.rot90(image, k=3)
+ return np.flipud(image)
+
+def load_images(file):
+ im = Image.open(file)
+ return np.array(im, dtype="float32") / 255.0
+
+def save_images(filepath, result_1, result_2 = None):
+ result_1 = np.squeeze(result_1)
+ result_2 = np.squeeze(result_2)
+
+ if not result_2.any():
+ cat_image = result_1
+ else:
+ cat_image = np.concatenate([result_1, result_2], axis = 1)
+
+ im = Image.fromarray(np.clip(cat_image * 255.0, 0, 255.0).astype('uint8'))
+ im.save(filepath, 'png')
diff --git a/README.md b/README.md
index 98aeab3..f9b3bd2 100644
--- a/README.md
+++ b/README.md
@@ -1,5 +1,8 @@
# GLADNet
+UPDATE: This fork contains Tensorflow 2.0 implementation of GLADNet in GLADNet2.0 directory.
+
+
This is a Tensorflow implantation of GLADNet
GLADNet: Low-Light Enhancement Network with Global Awareness. In [FG'18](https://fg2018.cse.sc.edu/index.html) Workshop [FOR-LQ 2018](http://staff.ustc.edu.cn/~dongeliu/forlq2018/index.html)